My Project of Youtube (Part 1)

A little bit about my YouTube project
Published on October 15, 2023 by Jeffry Troll
data science YouTube API
6 min READ
This is a walk-through project video on YouTube API creation that helps a lot.
Introduction:
YouTube has integrated into our daily lives massively in the past years, serving as an infinite wellspring of knowledge on a vast array of topics. My personal journey with YouTube has been a mix of guilt because of the time spent and proud satisfaction with the knowledge gained. This dichotomy sparked a curiosity within me, leading to a fascinating research question: What makes a YouTube channel successful?
Motivation:
With my wife, we shared a passion for culinary arts and food. Together, we’ve spent countless hours watching recipes, culinary experiments, and global food adventures on YouTube. This shared experience has stirred within us the aspiration to start our own YouTube channel. Fortunately, I have control over a project of data analysis of my preference, I embarked on a project that would offer practical insights into the basics of YouTube algorithm and content strategy.
In this blog post, I’ll share the journey of my data-driven exploration into YouTube’s inner workings. Join me as we dissect these insights and learn how data can inform and elevate our YouTube content creation.
Here is the repository of the project
Gathering the data:
As with any adventure, it began with the basics, setting up. So, I set up the Python environment by importing the necessary libraries, especially the one from Google.
from googleapiclient.discovery import build
Another important tool is the Google API client. I won’t get into the details about how to get a key because, at the beginning of this post, I shared a video that’s better than me in explaining that, so check that first. I just securely read the key from a file.
file = open("API_GOOGLE.txt", "r")
api_key = file.read()
file.close()
Once you have everything set up, it’s time to choose or identify the YouTube channels to analyze. Due to the nature of the project, I only selected a few channel IDs (Joshua Weissman, Guga Foods, and Nick DiGiovanni) and initiated our YouTube API client with the API key. This is like our gateway to accessing YouTube’s reservoir of data.
# Define a list of YouTube channel IDs
channel_id = ['UChBEbMKI1eCcejTtmI32UEw', 'UCfE5Cz44GlZVyoaYTHJbuZw', 'UCMyOj6fhvKFMjxUCp3b_3gA']
# Initialize YouTube API client
youtube = build('youtube', 'v3', developerKey=api_key)
- Channel Analysis: With the get_channel_stats function, we delved into each channel’s core, extracting vital statistics like content details and viewer engagement.
def get_channel_stats(youtube, channel_id):
request = youtube.channels().list(
part="snippet,contentDetails,statistics",
id = channel_id)
response = request.execute()
return response['items']
- Video List Compilation: Next, our get_video_list function acted like a net, capturing a comprehensive list of videos from each channel, ensuring even those hidden in the depths of YouTube were included.
def get_video_list(youtube, upload_id):
video_list = []
request = youtube.playlistItems().list(
part="snippet,contentDetails",
playlistId = upload_id,
maxResults=50
)
next_page = True
while next_page:
response = request.execute()
data = response['items']
for video in data:
video_id = video['contentDetails']['videoId']
if video_id not in video_list:
video_list.append(video_id)
if 'nextPageToken' in response.keys():
next_page = True
request = youtube.playlistItems().list(
part="snippet,contentDetails",
playlistId = upload_id,
maxResults=50,
pageToken=response['nextPageToken']
)
else:
next_page = False
return video_list
- Aggregating Video Data: The get_all_video_data_for_channels function was our aggregator, piecing together data from different channels into a cohesive whole.
def get_all_video_data_for_channels(youtube, channel_ids):
all_video_data = []
for ch_id in channel_ids:
channel_stats = get_channel_stats(youtube, [ch_id])
if not channel_stats:
continue
channel_name = channel_stats[0]['snippet']['title']
playlist_id = channel_stats[0]['contentDetails']['relatedPlaylists']['uploads']
video_list = get_video_list(youtube, playlist_id)
video_data = get_video_details(youtube, video_list, channel_name) # Passing channel name
all_video_data.extend(video_data)
return all_video_data
- Video Detail Mining: Finally, the get_video_details function was our data miner, extracting rich details from each video such as titles, publication dates, and various engagement metrics.
def get_all_video_data_for_channels(youtube, channel_ids):
all_video_data = []
for ch_id in channel_ids:
channel_stats = get_channel_stats(youtube, [ch_id])
if not channel_stats:
continue
channel_name = channel_stats[0]['snippet']['title']
playlist_id = channel_stats[0]['contentDetails']['relatedPlaylists']['uploads']
video_list = get_video_list(youtube, playlist_id)
video_data = get_video_details(youtube, video_list, channel_name) # Passing channel name
all_video_data.extend(video_data)
return all_video_data
With our data collected, it was time to give it structure. We poured our data into Pandas DataFrame, a versatile tool for data manipulation. Data, in its raw form, can be unwieldy. So, I refined it through:
- Identifying Collaborations: By analyzing video titles, we marked out collaborations, adding a layer of understanding to our analysis.
def get_all_video_data_for_channels(youtube, channel_ids):
all_video_data = []
for ch_id in channel_ids:
channel_stats = get_channel_stats(youtube, [ch_id])
if not channel_stats:
continue
channel_name = channel_stats[0]['snippet']['title']
playlist_id = channel_stats[0]['contentDetails']['relatedPlaylists']['uploads']
video_list = get_video_list(youtube, playlist_id)
video_data = get_video_details(youtube, video_list, channel_name) # Passing channel name
all_video_data.extend(video_data)
return all_video_data
- Time Transformation: Video lengths, initially cryptic in ISO format, were converted into understandable minutes.
def convert_to_minutes(iso_duration):
minutes_match = re.search(r'(\d+)M', iso_duration)
seconds_match = re.search(r'(\d+)S', iso_duration)
minutes = int(minutes_match.group(1)) if minutes_match else 0
seconds = int(seconds_match.group(1)) if seconds_match else 0
return minutes + seconds/60
df['duration_in_minutes'] = df['length'].apply(convert_to_minutes)
- Date Decoding: We transformed publication dates into Python’s datetime objects, adding a column to represent the day of the week, and unraveling patterns in publication schedules.
df['published'] = df['published'].apply(lambda x: datetime.strptime(x, "%Y-%m-%dT%H:%M:%SZ"))
def get_weekday(date_string):
return date_string.strftime("%A").lower()
df['day_published'] = df['published'].apply(get_weekday)
Final step, I exported this cleaned and transformed data into a CSV file.
Ethical Approach:
Standing on the precipice of launching our own YouTube channel, the ethical use of data becomes paramount. In today’s data-rich world, it’s all too easy to overlook the people behind the pixels. Throughout this project, respect for data privacy, viewer consent, and transparent practices have been more than mere buzzwords—they are the cornerstones of our methodology.
Even with Google providing the tools to scrape data from YouTube, recognizing the boundaries is critical. I’ve included an article that delves into this topic to provide a broader understanding: Understanding the Limitations of YouTube Data Scraping. Our analytical approach is designed to not only refine our content strategy but also to honor and comprehend the audience that breathes life into these statistics. Personal viewer information has remained untouched; our focus has been strictly on the data that is publicly available, aligning with YouTube’s terms of service and ethical data practices.
Conclusion:
Embarking on this exploration into YouTube’s algorithm has already been revelatory. Although I am only at the beginning of analyzing the data, it has started to illuminate a path through the intricate landscape of content creation. This project isn’t merely about decoding numbers; it’s about understanding the stories they tell.
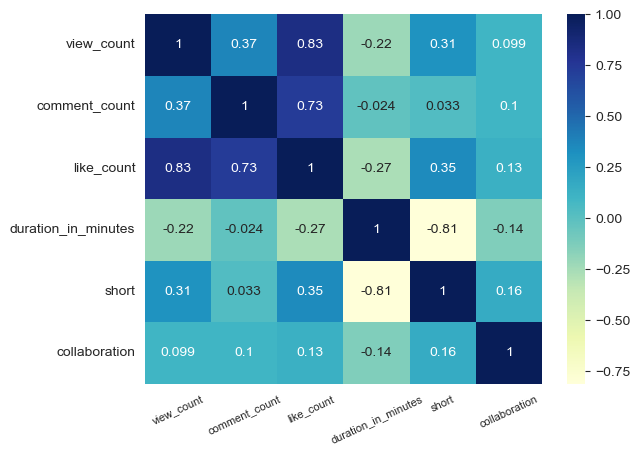
In my forthcoming post, I will dive deeper into the findings and share the insightful revelations from this analysis. Stay tuned as we continue to unravel the threads of YouTube success and lay the groundwork for our channel’s content strategy.